


Everything Suffers from Cold Starts
Run it


I pitch Lambda all the time. It's an amazing service that scales--in real-time--up to tens of thousands and down to zero. I encourage nearly all of the engineers I work with to begin with Lambdas as their compute layer (serverless first). Inevitably, I get the same pushback.
"Lambdas are nice" someone will say, "but you have to deal with cold starts." "Yes," I'll answer. Then I ask them "How are you dealing with cold starts today?" They crack a wry smile and say "We don't use Lambdas today; we don't have cold starts." "Au contraire," I reply, "you are positively swimming in cold starts right now." At this point you, who has overheard the whole conversation, rush up to say "But... I thought cold starts are unique to Lambdas?" Not in the least, no. Let’s dive into cold starts and see why they are truly everywhere.
What Is A Cold Start?
Think of a cold start as the penalty you pay for scaling out; it is the overhead of moving from supporting N traffic to N + P where, in Lambda's case, P is 1. The same thing happens if you are using containers or EC2 instances.
For example, when your auto-scaling policy determines you need to add more capacity (from N to N + P), it starts spinning those containers/instances up. The delay between capacity N and capacity N + P exists here, too. Except it happens in large chunks (because P is larger) instead of being distributed to each call (where P is 1). You essentially amortize the cost of that large delay, or cold start, over many calls, but it does occur.
Often, spinning up a new instance can take minutes. For example, bringing up a read-replica on AWS Aurora can take 5 to 15 minutes1. Bringing up a container in Fargate takes 1 to 5+ minutes, depending upon the size of the container2. In an enlightening post from 2022, Vlad Ionescu shows graph after graph of a simple "hello world" app on a container spending 30-140 seconds in a cold start. For contrast, Lambda measures cold starts in milliseconds. This time can impact your ability to serve customer traffic.
Concurrency
It's about concurrency. Think about a little man moving compute blocks in place to meet traffic demands. Lambda would be represented by small, unit-sized blocks. AppRunner, Fargate, or EC2 would have much larger blocks. How long each block takes to "make ready" is its cold start time. In general, the larger the block, the harder it is to push in place and the longer the cold start.
Cold starts existed before the cloud. Think about the cold start time involved in scaling up a new computer in your data center. You had to order the hardware, wait on delivery, allow your data center team to make room in the rack, install the unit, install all software and patches, and finally bring it online to receive traffic. That cold start is measured in days or weeks.
And it's even more prevalent; you suffer from cold starts. Think about the time it takes you to get dressed for work each morning and contrast that with what a fireman does. For a firefighter, everything is specially prepared for rapid "deployment." For example, a fireman may lay his protective pants and suspenders rolled down with his boots already inserted so he just needs to shove in his feet and pull up the suspenders. That's fast!

Examples of Horizontal Scaling And Cold Starts
What happens to your customers during one of these "cold starts"? That depends on both when you trigger a scale-out event and how many new requests are coming in. Let's look at a simple example.
Assume you are running a container (the same example works for EC2 instances) that can handle 4 concurrent requests per container. As our starting point, let's say you have one container running and it is serving 1 request. You also have a scaling policy that says "at 50% of request capacity, spin up another container". It takes 2 minutes to spin up a new container. Let's look at two graphs of new requests over time.
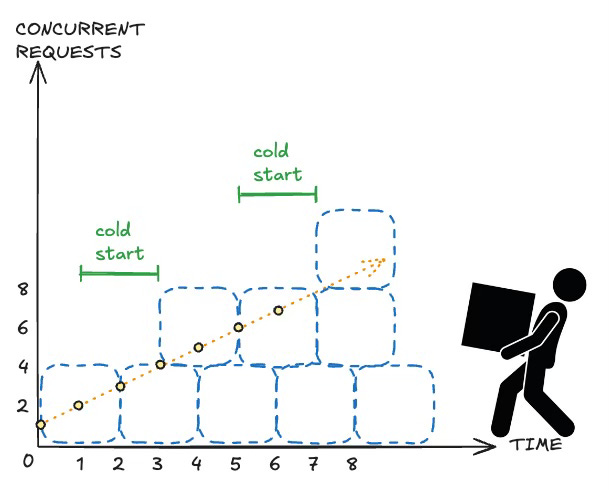
In the first graph, our rate of change is 1 new concurrent caller every 1 minute (linear, slope of 1). At t0, we are serving 1 request and our capacity for one container is 4 (75% available capacity). At t1, we serve 2 requests and, with our new available capacity of 50%, we trigger a scale out event. At t2, we are still waiting on the new container, but we can handle the 3rd concurrent request with our single container. At t3, we receive our new container and our capacity goes to 8 concurrent requests. As the graph shows, we are adding capacity in time to serve all requests. This is a successful scale-out. But, what happens if the rate of new requests is higher?

In the second graph, our rate of change is 2 new concurrent callers every 1 minute (linear, slope of 2). We start at the same t0 as before, serving one request for one container (75% available capacity). At t1, we serve 3 requests and--with our available capacity down to 25%--we trigger a scale out event. When t2 arrives, we only have capacity for 4 requests, but we now have 5. Customers are starting to see failures. At t3 we finish our first cold start and realize a new capacity of 8. However, our request count is now at 7 (13% available capacity) and we trigger another scale out event. At t4 we again fail to meet demand and customers are impacted. Given these linear rates of both request and capacity growth, we will have insufficient capacity for some requests every other minute.
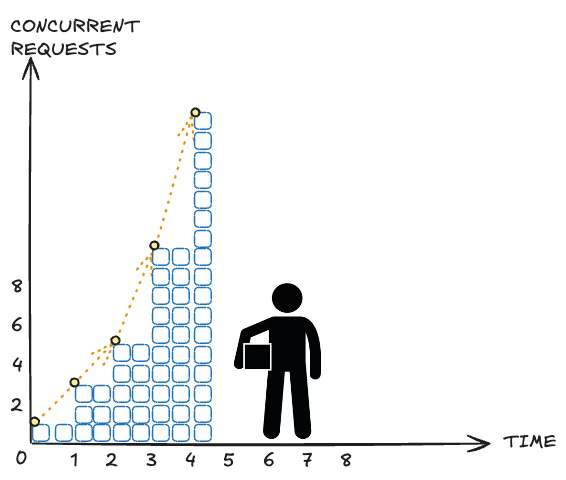
What does this look like for Lambda? Every additional concurrent request is a scale-out event, so at each new increase in the demand curve, we experience a small cold start and handle the call. There are no failed requests. Further, we never provision more capacity than what is needed at that moment. There is no leftover portion of the "box" we've stacked. I.e., there is no unused compute waiting for demand to increase.
Combating Cold Starts
There are really only two options available to you when faced with cold starts: deal with them or over-provision.
Deal with Them
Dealing with cold starts means eating the spin-up time. This is rarely used with instances/containers and often used with Lambda. You can optimize for minimal cold start impact by preferring certain runtimes, minimizing the size of your deployed bundle, and carefully choosing the libraries and layers you include. Even with all that, you are shaving off milliseconds, not minutes.
For Lambdas that are going to eat their cold start, this can be a fruitful exercise. For example, you'd choose JavaScript/NodeJS over .NET3, you'd choose to tree-shake and minify your code, and you'd choose to use made-for-Lambda tools like MiddyJS (over ExpressJS) and Lumigo (over DataDog4 or NewRelic).
Also, keep an eye on emerging tooling like AWS Labs' "Low Latency Runtime" for JavaScript. I have sample code that shows it reduces JavaScript cold start times below some compiled languages, including Golang. It's nearly as fast as Rust and you get to keep all your JavaScript tooling; win/win!
Over Provision
If you cannot scale in real time to meet your demand, you must scale ahead of time. And since nobody can predict the future minute-by-minute, second-by-second, this means guessing about the highest load you need to support and deploying that capacity right now in order to meet it later. Every business I've ever worked with used this strategy for their instance/container based workloads. Some were clever enough to schedule scale out/in events to meet predictable load changes (e.g., scale in at night) but all over-provisioned. None could scale to meet changes in real time.
For example, when I was at Amazon, each team presented its infrastructure costs to leadership every week. At each meeting, the EMs would point out any over-provisioning and say something like "You averaged 72% wasted capacity!" The team would nod, take notes, but ultimately accept the brow-beating. They knew they'd rather over-provision and lose a little money than fail to meet capacity, cause a SEV2 outage, and have to explain to some VP why they couldn't handle the load.
In Lambda, you over provision by using a feature called Provisioned Concurrency. You can specify that some of your Lambdas will stay hot irrespective of demand and, logically, you pay for those Lambdas whether anyone uses them or not. If your Lambda cold start times are too large to eat, you have to consider over provisioning of some sort.
But, even without Provisioned Concurrency, Lambda relies on over provisioning at the hardware layer. While the VMs Lambda uses (Firecracker) are lightning fast and ephemeral, the underlying bare-metal machines that run Firecracker are huge and have to be up and running (pre-provisioned) long before loading any particular VM. Except in this case, AWS manages the over provisioning and "wasted" capacity for you. The more efficient they are, the cheaper they can provide Lambda to us.
In Closing
As we've seen, cold starts are everywhere and it is a mistake to think they only apply to Lambda. Every scale-out event will incur some manner of cold start, whether instances, containers, or Lambdas. If you choose to use Lambdas, do the work to minimize your cold starts. It makes eating them much more palatable.
Have you had a different experience with cold starts? Let me know. Leave a comment on this article or email me directly. I'm interested to hear your experience. Have fun!
Further Reading
Vlad Ionescu: Scaling containers on AWS in 2022
GitHub: awslabs/llrt
AWS Documentation: Understanding the Lambda execution environment
Amazon Science: How AWS's Firecracker virtual machines work
GitHub: MiddyJS
From a personal conversation with AWS Aurora team April 2023
https://stackoverflow.com/a/54668770/266427
I led an entire development team through this exercise in 2016. Goodbye C#. Hello JS.
I, and many others, observed cold start times increase by a full second(!) when using DataDog's Lambda layer. I have graphs. Here’s the issue in GH.